Statistics in Engineering
With examples in
MATLAB® and R
Andrew Metcalfe, David Green, Tony Greenfield,
Mahayaudin Mansor, Andrew Smith and Jonathan Tuke.
Chapter 2 solutions to odd numbered exercises
In these solutions we use natural numbers in ascending order as seeds for pseudo-random number generators.
You might find this link an amusing distraction
Remember that if solutions depend on random numbers your answers will differ slightly from ours, but should be similar.
Exercise 2.1
The following R script generates 10 sequences of 20 pseudo-random digits and prints
each sequence as a column. Your sequences will be different unless you used R with the same
seed i
set.seed(1)
randig=matrix(rep(0,200),nrow=20,ncol=10)
for (i in 1:10){
randig[,i]=sample(0:9,size=20,replace=TRUE)
}
print(randig)
[,1]
[,2]
[,3]
[,4]
[,5]
[,6]
[,7]
[,8]
[,9]
[,10]
[1,]
2
9
8
9
4
6
9
6
2
2
[2,]
3
2
6
2
7
3
4
6
8
1
[3,]
5
6
7
4
3
2
4
2
4
8
[4,]
9
1
5
3
3
9
1
2
7
5
[5,]
2
2
5
6
7
6
7
7
8
8
[6,]
8
3
7
2
2
2
4
4
4
1
[7,]
9
0
0
4
7
1
5
1
0
7
[8,]
6
3
4
7
1
4
2
7
3
7
[9,]
6
8
7
0
2
9
2
1
7
9
[10,]
0
3
6
8
1
5
5
8
3
5
[11,]
2
4
4
3
2
9
5
6
6
7
[12,]
1
5
8
8
0
7
0
5
8
3
[13,]
6
4
4
3
6
3
0
3
8
1
[14,]
3
1
2
3
8
4
6
4
3
9
[15,]
7
8
0
4
7
1
9
5
3
2
[16,]
4
6
0
8
7
0
5
1
8
5
[17,]
7
7
3
8
4
7
5
5
6
1
[18,]
9
1
5
3
4
1
5
0
7
8
[19,]
3
7
6
7
8
4
9
2
6
3
[20,]
7
4
4
9
6
6
5
2
9
7
Sequence
1
2
3
4
5
6
7
8
9
10
(i)
1
0
2
2
3
0
5
3
2
1
(ii)
2
3
2
2
2
2
2
3
2
1
(iii)
0
0
0
0
0
0
1
0
0
0
(iv)
0
0
1
1
3
0
1
3
0
1
notes:
The \(555\) in Sequence \(7\) gives two cases of the same digit repeated. The instances of three consecutive digits are \(123\) and \(345\)
in Sequence \(2\) and \(345\) in Sequence \(8\)
There are \(19\) times \(10\) consecutive pairs of digits. There are \(19\) instances of the same digit
repeated. The proportion is \(19/190\) which is \(0.1\). By chance for these sequences, this happens to precisely match
the proportion we would expect in a very long sequence. This proportion is \(0.1\) because the first digit of a pair can
be any digit and there is a \(1\) in \(10\) chance that the second digit will be identical.
proportion.
The longest run of digits in natural order is \(3\). This occurred three times. With these sequences
there is no longer run, and no additional runs of \(3\) digits, if they are read as one long sequence - reading down columns.
There are \(18\) times \(10\) consecutive triples. We would expect \(0.01\) of a very long sequence of triples to be the
same digit repeated three times. This is because the first digit can be any digit and there is a \(1\) in \(100\) chance that
the same digit will occur in the next two positions. There was one instance, \(555\), in the sequences which is consistent
with an expected number of \(180/100 = 1.8\). Notice that the mathematical expectation need not be an integer.
If the sequences of length \(20\) are considered as sequences of \(10\) disjoint pairs of digits there are \(10\) instances
of the same digit being repeated. The proportion of \(10/100\) same digit repeated happens to precisely match the expected
proportion in a very long sequence. Note: Following a similar argument to (iii) we would expect \(1.8\) instances of a run of three consecutive digits
in natural order. That is, in a very large number of sets of ten sequences of length \(20\) the average number of three consecuitve
digits in natural order would be \(1.8\). We have just one set, and the observed \(3\) instances is quite consistent with the
expected \(1.8\).
Exercise 2.3
The \(5\) blocks of \(4\) binary digits give the following sequence of integers:
\(1 12 7 2 9\)
ignoring the \(12\) leaves \(1729\) (Hardy-Ramanujan number).
The \(4\) blocks of \(4\) binary digits give the following sequence of integers:
\(14 4 10 2\)
and these are \(E 4 A 2\) in hexadecimal.
Exercise 2.5
Each lifeboat has a \(2\) in \(100\) chance of selection for every pair of digits.
The sequence of two digit integers is:
\(62 42 83 08 81 35 16 52 86 70\)
The selected lifeboats would be \(12 - - 8 - - - 2\)
Associate \(01, ... , 12; 21, ... , 32; 41, ... , 52; 61, ... , 72; 81, ... , 92\)
with lifeboats \(1, .... , 12\).
Then each lifeboat has a \(5\) in \(100\) chance of selection for every pair of digits.
The sequence of two digit integers is:
\(62 42 83 08 81 35 16 52 86 70\)
The selected lifeboats would be \(2 - 3 8\)
Notice that selection is without replacement.
The lifeboats are not equally likely to be selected.
Lifeboats \(12, 1, 2, 3\) have a \(9\) in \(100\) chance of selection for every pair of digits
whereas the other lifeboats have an \(8\) in \(100\) chance of selection.
This is because \(96, 97, 98, 99\) correspond to lifeboats \(12, 1, 2, 3\).
Exercise 2.7
The following R script generates a sequence of length \(6075\), including the seed I0, after which it repeats.
The order appears to be haphazard. The distribution of digits is almost discrete unifom, and a plot of the
\((i+1)^{th}\) digit against the \(i^{th}\) does not show any patterns. Is the choice of seed value critical?
#Exercise 2.7
I0=1234
a=106;b=1283;m=6075
K=6074
I=rep(0,K)
I[1]=(a*I0+b)%%m
for (i in 2:K){
I[i]=(a*I[i-1]+b)%%m
}
print(sort(I))
plot(as.ts(I))
D=floor(10*I/m)
print(D)
print(stem(D))
plot(I[1:(K-1)],I[2:K],pch=".")
#note the sequence repeats after m integers have been generated
Im=(a*I[K]+b)%%m
print(Im)
Exercise 2.9
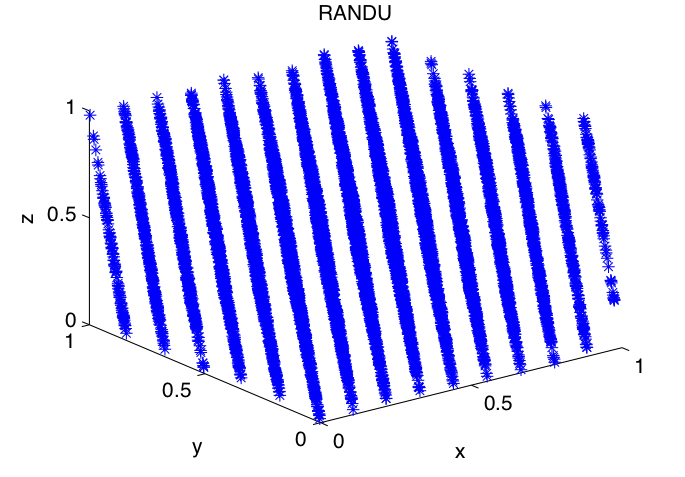
The following R script generates a sequence of \(30000\) numbers \(U_i\) using RANDU given in Example 2.3 and creates
a set of \(10000\) triples \((x, y, z) = (U_i,U_i+1,U_i+2)\) from the generated \(30000\) data.
It also plots the triples and angles the 3D plot to show a \(15\) well defined planar structure of the data.
# This script generates data from an lcg (RANDU in particular)
# plots a data histogram, makes triples and plots a scatterplot in 3d
require('scatterplot3d')
N=30000; # The number of data to produce
Z0 = 1; # the initial seed value
a=65539;
c=0;
m=2^(31);
myData=numeric(length=(N+1))
myData[1] = Z0
for (i in 2:(N+1)){
myData[i] = ((a*myData[i-1]+c)%%m)
}
myData=myData[2:(N+1)]/m
hist(myData)
myTriples<-array(0,dim=c(10000,3))
for (i in 1:10000){
myTriples[i,] = myData[(3*(i-1)+1):(3*i)]
}
scatterplot3d(myTriples[,1],myTriples[,2],myTriples[,3],angle=160,pch='.')
This is because \(2^{32} (mod 2^{31}) = 0\) and so the form shows that
\(9 Z_i - 6 Z_{i+1} + Z_{i+2}\) is a multiple of \(2^{31}\).
Dividing by \(2^{31}\) to get a number in \([0,1]\), we get the triplets
\((x, y, z) = (Z_i, Z_{i+1}, Z_{i+2})/2^{31}\).
Then the plot actually shows that all triplets lie in 15 planes given by
\(9x - 6y + z = w\), where \(w = -5, -4, ... , 9\).
The latter resultant values of \(w\) can easily be gained by direct calculation on the triplets.
Thus the lcg RANDU produces random numbers in \((0,1)\), but there are strong correlations between subsequent
values (serial correlation).
Exercise 2.11
Selection is random such that each of the pumps available for selection is equally likely to be chosen.
There are \(5F\) and \(12G\). Assume sampling without replacement. Numerical answers correct to \(4\) decimal places
\(A = (A \; and \; not \; B) \; or \; (A \; and \; B)\)
The events on the right are mutually exclusive so by Axiom 2
\(P(A) = P(A \; and \; not \; B) + P(A \; and \; B)\)
\(A\; or \; B = (A \; and \; not \; B) \; or\; (A \; and \; B) \; or \; (not \; A \; and \; B)\)
The events on the right are mutually exclusive so by Axiom 2
\(P(A \; or \; B) = P(A \; and \; not \; B) + P(A \; and \; B) + P(not \; A \; and \; B)\)
Start from (ii)
\(P(A \; or \; B) = P(A \; and \; not \; B) + P(A \; and \; B) + P(not\; A \; and\; B)\)
Now use (i) to replace \(P(A \; and \; not \; B)\) by \(P(A) - P(A \; and \; B)\), and hence obtain
\(P(A \; or \; B) = P(A) - P(A \; and \; B) + P(A \; and \; B) + P(not \; A \; and \; B)\)
Exchanging \(A\) for \(B\) in Equation (i) leads to
\(P(B) = P(not \; A \; and \; B) + P(A \; and \; B)\)
and subtitution for \(P(not \; A \; and \; B)\) gives
\(P(A \; or \; B) = P(A) - P(A \; and \; B) + P(A \; and \; B) + P(B) - P(A \; and \; B) = P(A) + P(B) - P(A \; and \; B)\)
Therefore, the addition rule is a consequence of the axioms of probability.
We are given: \(P(H) = 0.20, P(D) = 0.15, P(D|H) = 0.40\)
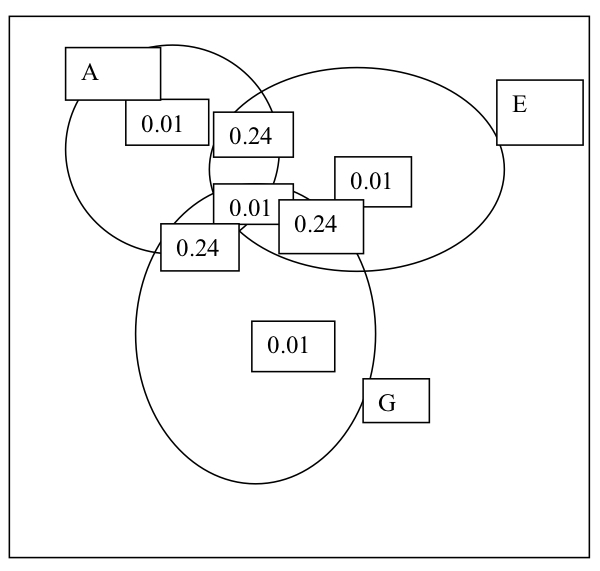
The Venn diagram is not drawn to scale. Start with \(0.01\) for the intersection of all three events and then work out to
the intersections of two events, and notice that this leaves \(0.01\) for the three events of the form, for example
\((A \; and \; not \; E \; and \; not \; G)\).
\(P(A \; and \; E) = 0.25 = P(A)P(E) = 0.50 \times 0.5\) and similarly for \(P(A \; and \; G), P(E \; and \; G)\).
\(P(A \; and \; E \; and \; G) = 0.01\) which is not equal to \(0.5 \times 0.5 \times 0.5 = 0.125\).
The three events are not independent.
Exercise 2.21
We are told errors occur independently.
\(1 - 0.99^2 = 0.0199\)
\(1 - 0.99^3 = 0.0297\)
\(1 - 0.99^n\)
Assuming all the digits equally likely to be any of \(\{0, 1, ..., 9\}\), the probability is
\(0.1^{12} = 10^{-12}\).
Exercise 2.23
\(P(functions) = 1 - P(system fails) = 1 - P((A\; or \; B \; fail) \; and \; C \; fails) = 1 - (a + b - ab)c\)
Alternatively
\(P(functions) = P((A \; and \; B \; work) \; or \; C \; works) = (1-a)(1-b) + (1-c) - (1-a)(1-b)(1-c)\)
Exercise 2.25
Imagine a long period of \(N\) years. Suppose the annual maximum flood exceeds a critical level \(c\) on \(k\)
years during this period.
The probability of exceeding \(c\) in any one year is \(p = k/N\) from the relative
frequency definition of probability.
The average time between events (ARI) is \(N/k\) years, and this is \(1/p\).
The probability of at least on exceedance is the complement of no exceedance and if exceedances are independent
this equals \(1 - (1 - 1/T)^n.
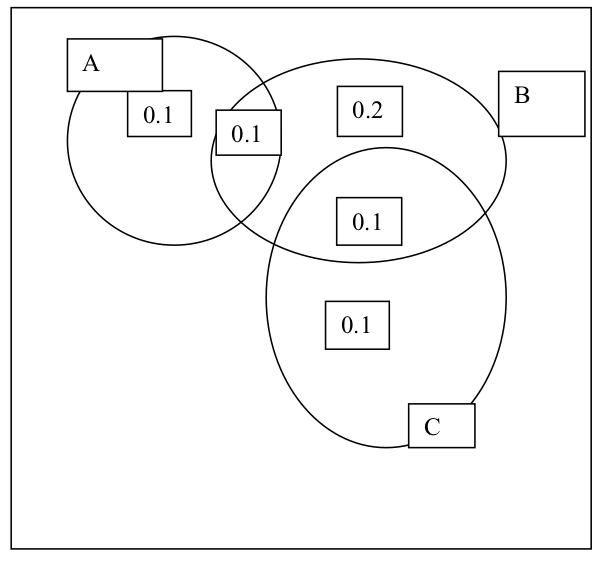
It is not true.
Notice that \(B\) favoring \(A\) is equivalent to \(P(A \; and \; B) > P(A)P(B)\), and if \(B\) favors \(A\)
so too \(A\) favors \(B\). A counter example is shown in the figure.
In the figure \(P(A) = 0.2, P(B) = 0.4\), and \(P(A \; and \; B) = 0.1\), so \(B\) favors \(A\)
\(P(C) = 0.2, P(B) = 0.4\), and \(P(C \; and \; B) = 0.1\), so \(C\) favors \(B\)
\(P(A \; and \; C) = 0\), so \(C\) does not favor \(A\).
Exercise 2.33
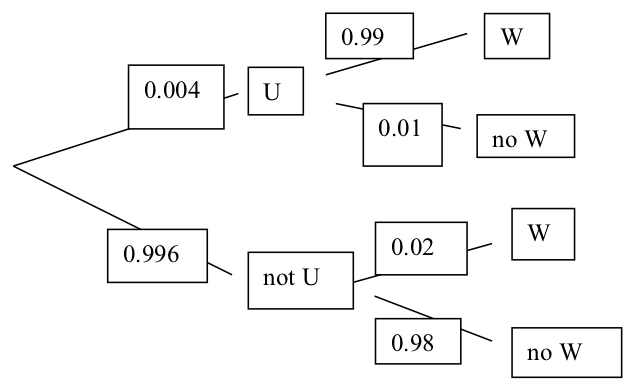
The probability of flooding is \(0.3 \times 0.2 + 0.6 \times 0.4 + 0.1 \times 0.5 = 0.35\)
This is an application of the law of total probability. It is also an example of a weighted average.